Enterprise Retrieval-Augmented Generation (RAG) - Part 1
Enterprises generate massive volumes of unstructured data that traditional search and summarization methods cannot manage effectively. Retrieval-Augmented Generation (RAG) solves this by combining semantic retrieval with large language models, grounding answers in real, current, and private enterprise knowledge without retraining. With well-designed pipelines covering chunking, embeddings, vector stores, and retrieval strategies, RAG delivers scalable, accurate, and dynamic AI assistants that transform static repositories into live knowledge systems.
Date
September 25, 2025
Topic
Agentic AI
Share
Why RAG Matters
Enterprises today manage ever-growing reservoirs of unstructured data - HR documents, contracts, policies, technical specifications, research reports, call transcripts, and much more. These repositories can easily span terabytes, and yet the challenge remains the same: how do we make all this knowledge instantly usable by an Agentic AI application? Keyword search is brittle and surface-level, brute force scanning is prohibitively expensive, and pre-summarization discards nuance and context. Retrieval-Augmented Generation (RAG) has emerged as the architectural pattern that addresses these challenges. By combining semantic retrieval with large language models (LLMs), RAG allows enterprises to deliver AI assistants that ground every answer in real, current, and private institutional knowledge, without the need for costly fine-tuning.
The Challenge: Large Knowledge Repositories
Real-time brute force search
Attempting to search hundreds of gigabytes of documents every time a query is issued is computationally infeasible. Even with distributed systems, the latency is high, indexing is inefficient, and the overall user experience becomes frustrating. A system that requires a full scan per request will fail to scale in production environments.
Pre-summarizing into chunks
Some teams attempt to preprocess documents by summarizing them into small, searchable chunks. While this reduces query-time load, it introduces major risks: oversimplification, missing critical context, and losing traceability back to the original source. For domains such as legal, compliance, or R&D, these inaccuracies can be unacceptable.
Relying solely on model pre-training
LLMs such as GPT models are trained on broad public data. Without augmentation, they lack visibility into private corporate information. Worse still, their knowledge cutoff dates mean that responses can quickly become outdated, creating a mismatch between what the assistant says and what the company actually does.
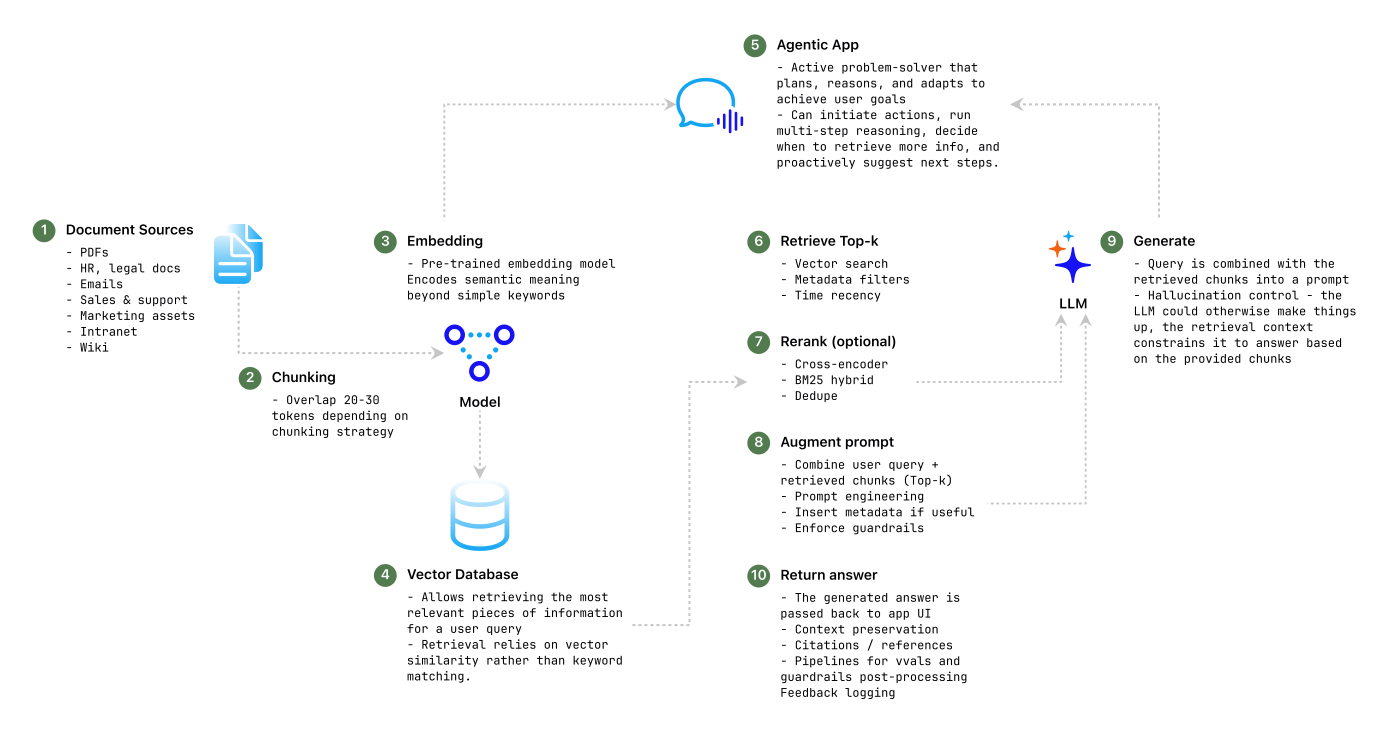
How RAG Works: Retrieval → Augmentation → Generation
Retrieval
The first step is semantic retrieval. Both documents and user queries are transformed into vector embeddings using models that capture semantic meaning rather than just keywords. These embeddings are stored in a vector database optimized for similarity search. When a user asks a question, the query is embedded and compared against millions of document vectors to identify the most relevant chunks. This ensures that “pets allowed” and “dogs permitted” are recognized as conceptually similar, whereas traditional keyword search would fail.
Augmentation
Once relevant chunks are retrieved, they are injected into the LLM’s prompt at runtime. This augmentation gives the model the context it needs to generate grounded responses. Unlike pre-training, this method allows the AI to reference dynamic, domain-specific knowledge that can evolve daily. The augmentation step is what turns a generic AI model into a company-specific copilot.
Generation
Finally, the LLM generates a response that blends the user’s original query with the augmented context. Because the context is drawn from real enterprise documents, the answer is more accurate, traceable, and actionable. Importantly, no retraining or fine-tuning of the LLM is required, which keeps the solution cost-efficient and flexible.
A representative RAG pipleine
Designing the RAG Pipeline
Chunking
Chunk size and overlap play a decisive role in retrieval quality. For example, a 500-token chunk with a 100-token overlap works well for narrative documents, ensuring that context spans across section boundaries. For legal contracts, larger chunk sizes preserve clauses, while conversational transcripts may require smaller, overlapping segments to retain continuity. Poorly tuned chunking leads to fragmented results or context dilution.
Embedding Models
Selecting an embedding model is a balance between accuracy, latency, and cost. Compact models like all-MiniLM-L6-v2 are lightweight and performant, making them suitable for large-scale ingestion pipelines. Higher-dimensional models provide finer granularity but demand more storage and slower retrieval. Embedding choice should align with enterprise priorities, speed for real-time chat, or accuracy for compliance-heavy domains.
Vector Stores
Databases such as LanceDB, Pinecone, and Qdrant are designed to handle millions of embeddings and return top-k results with low latency. The right vector store should support persistence, sharding, and hybrid search (vector + metadata filters) to meet enterprise requirements. Scalability and integration with security layers are critical in production deployments.
Retrieval Strategies
Beyond vector similarity, retrieval strategies include filtering by metadata (e.g., document type, time, department) and applying similarity thresholds to suppress low-confidence matches. These controls dramatically reduce hallucinations by ensuring that only strong matches are included in the augmented prompt.
Integration Layer
The pipeline is surfaced through APIs or lightweight interfaces such as Flask applications for testing, or enterprise-grade chat platforms for production. The integration layer must manage rate limits, authentication, and user experience, bridging technical infrastructure with business usability.
Why Enterprises Should Care
Grounded intelligence
Every AI-generated response is linked back to original documents, creating a system of record that is auditable and trustworthy. Grounded intelligence means every AI-generated response can be directly traced back to the original documents that informed it. This linkage transforms AI systems from “black box” tools into auditable and verifiable sources of knowledge, giving enterprises confidence that answers are accurate, compliant, and based on real institutional data. In industries such as finance, healthcare, or legal, where accountability is paramount. This traceability ensures that insights are not only useful but also defensible under regulatory scrutiny.
Beyond compliance, grounding responses in original documents builds trust with end users and decision-makers. Employees know they can rely on the assistant’s outputs, while leaders gain peace of mind that recommendations are backed by documented facts, not guesswork or hallucination. Over time, this transparency fosters adoption, turning the AI from a novelty into an essential decision-support system that strengthens organizational knowledge management.
Dynamic adaptability
Because the AI retrieves information from an always-current vector database, there is no need to retrain models every time data changes. This slashes maintenance costs and accelerates time to value. Dynamic adaptability ensures that RAG systems remain relevant in fast-changing enterprise environments. Because the AI retrieves information from a continuously updated vector database, organizations don’t need to retrain or fine-tune large language models every time new data is introduced. This eliminates the costly and time-consuming retraining cycles common with traditional AI approaches, while also ensuring that responses always reflect the latest policies, contracts, research, or operational data. As a result, businesses benefit from lower maintenance overhead, faster deployment, and quicker return on investment.
Just as important, this adaptability allows AI assistants to evolve in lockstep with the enterprise. Whether new regulations are published, new products are launched, or internal processes are updated, the RAG pipeline can immediately surface and ground responses in the latest information. This real-time alignment helps maintain accuracy and trust while giving employees confidence that the AI reflects the organization’s current reality. In practice, dynamic adaptability transforms AI assistants from static tools into living systems of knowledge that scale with the pace of business change.
Scalable architecture
RAG pipelines are built to handle terabytes of data while delivering real-time responses. This makes them future-proof for organizations expecting exponential data growth. Scalable architecture in RAG pipelines ensures that enterprises can manage ever-expanding data volumes, from gigabytes to terabytes, without sacrificing performance. By leveraging vector databases, optimized retrieval strategies, and efficient embedding models, these systems deliver real-time responses even as repositories grow exponentially. This design allows organizations to future-proof their AI initiatives, ensuring that assistants remain responsive and effective as data demands intensify.
Beyond raw scale, a well-architected RAG pipeline adapts seamlessly to evolving business needs and technology stacks. It can integrate with authentication layers, support hybrid search, and distribute workloads across clusters, all while maintaining low latency and high accuracy. This flexibility not only guarantees that enterprises can handle current challenges but also positions them to scale confidently into new markets, departments, and use cases, turning data growth into a competitive advantage rather than an operational burden.
Reduced hallucinations
By carefully tuning retrieval thresholds and grounding answers in retrieved content, RAG systems minimize the risk of fabricated responses, a critical factor for industries like healthcare, finance, and legal. Reduced hallucinations are one of the most valuable outcomes of a well-designed RAG system. By tuning similarity thresholds, filtering weak matches, and grounding every response in retrieved enterprise documents, RAG significantly minimizes the risk of fabricated or misleading outputs. This reliability is especially critical for highly regulated industries such as healthcare, finance, and legal, where even a small error could result in compliance violations, reputational damage, or financial loss. Grounding responses in verified content ensures that decision-makers, employees, and customers can trust the system’s outputs.
Equally important, reducing hallucinations improves adoption and confidence in AI systems across the enterprise. When users see that answers consistently reflect source documents, they are more likely to rely on the assistant for day-to-day operations, research, and decision support. This trust transforms AI from a novelty tool into an integral part of workflows, helping organizations unlock productivity gains while reducing the risks associated with unverified AI outputs. In this way, hallucination reduction not only protects organizations but also accelerates their ability to operationalize AI at scale.
Key Takeaway
Retrieval-Augmented Generation is not just another AI buzzword. It is a practical, production-ready architecture that bridges the gap between generic LLMs and proprietary enterprise data. With well-designed chunking strategies, robust embedding pipelines, and tuned retrieval layers, organizations can deploy AI assistants that transform static document repositories into live, intelligent knowledge systems. Done right, RAG enables the shift from chatbots that “sound smart” to copilots that are smart, because they’re grounded in your own data.
Note: This article is part one of a two-part series. Following this, part two will explore RAG considerations and techniques for structured data in the enterprise.