RAG vs. Long Context: Choosing the Right Memory Architecture for Enterprise AI
RAG and Long Context solve the same problem - getting enterprise data in front of an LLM through fundamentally different mechanisms, each with distinct tradeoffs around scale, cost, reasoning quality, and failure modes. Choosing between them, or combining both in a hybrid architecture, is one of the most consequential infrastructure decisions in enterprise AI deployment.
Date
March 31, 2026
Topic
Agentic AI
Share
Every AI initiative eventually runs into the same wall. Your team has selected a model, stood up the infrastructure, and built the first prototype - and then someone asks the obvious question: how does this thing know about our data?
It is the right question, and the answer is not as simple as “connect it to the database.” Large language models do not query systems in real time. They reason over whatever information is placed in front of them at the moment of inference. Getting enterprise knowledge - policies, records, contracts, operational data into that window is an architectural decision, and two dominant patterns have emerged to solve it. Choosing between them, or knowing when to combine them, will determine the cost, reliability, and scalability of nearly every AI system you build.
This article gives IT and data leaders a clear framework for that decision.
Why Models Do Not Know Your Data
A large language model is trained on a fixed corpus, a snapshot of text assembled before a cutoff date. Everything after that cutoff, and everything that was never in the training data to begin with (your EHR records, your supplier contracts, your production telemetry), is invisible to the model. It will not find it on its own, and it will not admit that cleanly. It may instead produce a confident-sounding answer based on nothing relevant.
The solution is context injection: placing the relevant information directly into the prompt at query time, so the model reasons over your data rather than around it. Two architectures do this in fundamentally different ways.
Two Approaches to Context Injection
RAG vs long context architecture
Retrieval Augmented Generation (RAG)
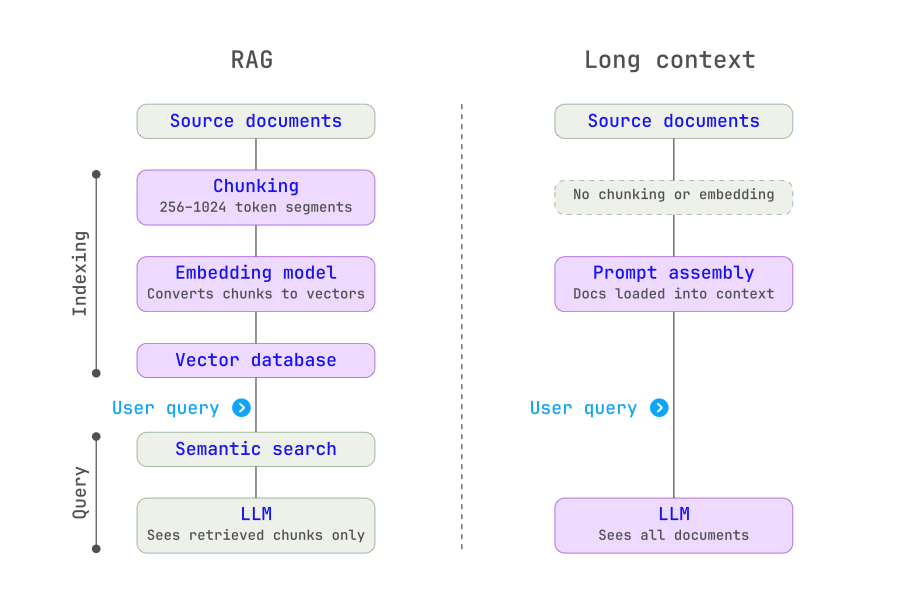
RAG was built for a world where context windows were small, a few thousand tokens at most. The architecture works in two phases.
During indexing, documents are broken into smaller segments (typically a few hundred tokens each), converted into numerical vector representations using an embedding model, and stored in a vector database. This happens once, offline, before any queries are run.
At query time, the user’s question is converted into the same vector format and matched against the index using semantic similarity search. The top matching segments are retrieved and injected into the prompt alongside the question. The model generates an answer based only on what was retrieved.
The key insight: RAG outsources the “find what is relevant” problem to a retrieval system before the model ever sees the question.
Long Context Injection
Long Context takes the opposite approach. Instead of selecting relevant chunks in advance, the entire document, or a large portion of the corpus is loaded directly into the model’s context window. The model’s internal attention mechanism handles the work of locating and synthesizing relevant passages.
This was impractical five years ago. Early models supported only a few thousand tokens of context. Today, leading models support context windows of one million tokens or more, enough to hold a complete clinical protocol library, several years of supplier contracts, or an entire product knowledge base in a single prompt.
The key insight: Long Context moves the “find what is relevant” problem inside the model, where the attention mechanism handles it natively.
Where Each Architecture Wins - and Where It Struggles
RAG vs long context decision framework
The Case for Long Context
Architectural simplicity. A RAG pipeline has many components: ingestion pipelines, chunking logic, embedding models, vector databases, retrieval services, re-ranking layers, and orchestration code. Each is a system that can fail, drift, or require maintenance. Long Context replaces all of that with a single model call. For enterprise teams that need to move fast, this reduction in complexity is significant.
No silent retrieval failures. The most dangerous failure mode in RAG is one you cannot easily see: the retrieval step returns the wrong chunks, and the model generates a plausible-sounding answer based on incomplete or irrelevant information. There is no error. No alert fires. The answer is simply wrong. Long Context eliminates this failure class entirely. The model sees all of the relevant material, by design.
Cross-document reasoning. Many of the most valuable enterprise questions require synthesizing information distributed across multiple documents. “How does our current supplier SLA compare to the terms we negotiated in 2021?” or “What are the discrepancies between this clinical trial protocol and our standard operating procedures?” are questions that span documents. RAG returns isolated chunks; Long Context attends to all documents simultaneously.
Healthcare example: A regional health system needed its AI assistant to answer complex clinical questions by reasoning across a patient’s full longitudinal record - notes, labs, imaging reports, and medication history spanning multiple years. A RAG-based approach kept missing critical context because relevant information was spread across dozens of documents, no single chunk of which triggered the retrieval threshold. Switching to a Long Context architecture, with the full record loaded per query session, eliminated the retrieval gaps and allowed the model to reason holistically across the patient timeline.
The Case for RAG
Cost at scale. Long Context requires re-processing the full document set on every query. A clinical informatics team running thousands of queries per day against large document corpora is processing enormous token volumes at input pricing. RAG processes each document exactly once at indexing time. Subsequent queries pay only for the retrieved chunks and the generated answer. At enterprise query volumes, this cost difference compounds rapidly.
Attention quality on specific facts. Larger context windows do not guarantee proportionally better recall. Research has consistently documented the “lost in the middle” effect: models show stronger recall for content near the beginning and end of the context window, with degraded performance for material in the middle. When the answer is one paragraph buried in a 300-page document, injecting the full document may not reliably surface it. RAG mitigates this by presenting the model with a focused, high-signal context, typically the top ten to twenty chunks rather than a large, diluted one.
Unbounded enterprise data lakes. Even million-token context windows represent a hard ceiling. Most enterprise knowledge bases years of supplier records, clinical documentation, customer histories, regulatory filings are measured in terabytes, not tokens. RAG is the only architecture that scales to this volume. It indexes the full corpus and selects a relevant slice for each query; the model never needs to see everything at once.
Manufacturing example: A global industrial equipment manufacturer deployed an AI assistant for field service engineers, drawing on a knowledge base covering thousands of machine models, service bulletins, parts catalogs, and troubleshooting guides spanning two decades. Long Context was impractical: the corpus was far too large for any context window. RAG allowed engineers to query the full knowledge base conversationally, the retrieval layer surfaced the relevant service bulletins and parts diagrams for the specific machine model and fault code, and the model generated a structured troubleshooting response. Query latency stayed under two seconds even at scale.
A Framework for Choosing
The question is not which architecture is better - it is which architecture fits a given workload. Four dimensions should drive the decision.
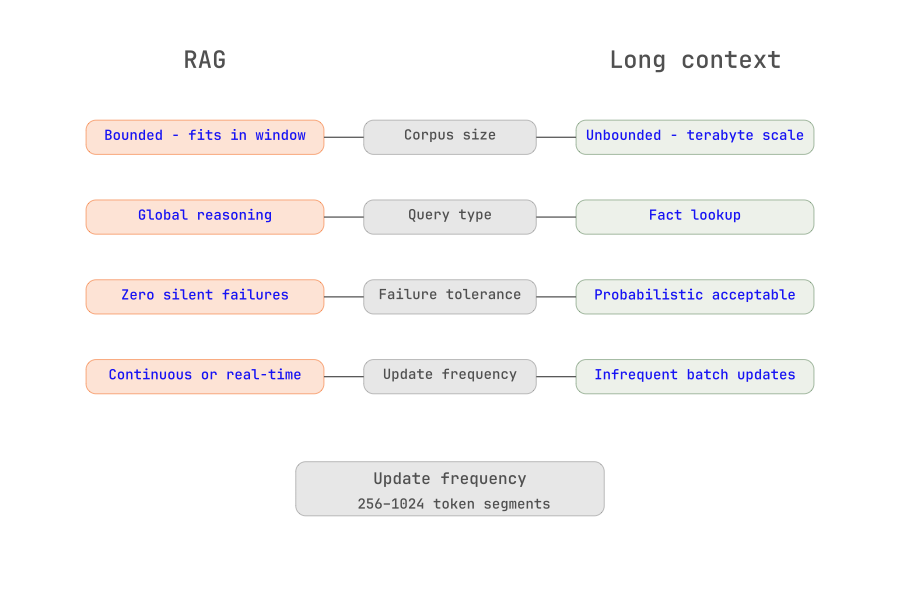
Corpus size. If the relevant knowledge base fits within the model’s context window - a bounded policy document set, a specific contract collection, a single product’s documentation - Long Context is worth evaluating. If the corpus spans multiple systems and years of records, RAG is the only architecture that scales.
Query structure. Queries that require global reasoning across an entire document - summarize this contract, find all inconsistencies in this clinical protocol, compare these two supplier proposals - favor Long Context. Queries that are essentially fact lookups - what does section 4.2 say, find the SLA penalty clause, retrieve the torque specification for this part - favor RAG, where targeted retrieval produces a focused, high-signal context.
Failure mode tolerance. In regulated industries - healthcare, financial services, manufacturing compliance, silent retrieval failures carry real risk. A missed drug interaction, an overlooked contract obligation, a misread safety specification: these are not acceptable failure modes. Long Context, by ensuring the model sees all relevant material, produces more auditable and reproducible behavior. This is a meaningful differentiator for compliance-sensitive deployments.
Update frequency. For knowledge bases that update continuously - production telemetry, patient records, live procurement data, long Context has an operational advantage: insert the latest version of the document and the model reasons over current information immediately. RAG requires re-embedding and re-indexing on every update, which introduces pipeline latency and operational overhead. For static corpora, this distinction disappears.
When to use Long Context
Reach for Long Context when the corpus is bounded and fits within the model’s window, when queries require deep cross-document synthesis, when the stakes of a missed retrieval are high, and when the team needs to move fast and minimize pipeline complexity. Contract analysis, clinical protocol review, policy comparison, and code review are natural fits.
When to use RAG
Reach for RAG when the corpus is large or growing, when query volume is high and inference cost matters, when queries are primarily fact lookups rather than synthesis tasks, and when the knowledge base updates frequently. Field service knowledge bases, enterprise search across large document repositories, and customer-facing AI assistants over product catalogs are natural fits.
The Hybrid Pattern: Combining Both
In practice, many mature enterprise deployments use both architectures in sequence. The pattern: RAG to narrow the search space, Long Context to reason deeply over the results.
Corpus-scale retrieval (RAG layer). Vector search filters a terabyte-scale corpus down to the ten to twenty most relevant documents or sections. This step handles the scale problem that Long Context alone cannot.
Context assembly (orchestration layer). Retrieved documents are assembled, de-duplicated, and ordered. Domain-specific re-ranking logic can be applied here - for example, prioritizing more recent documents or higher-authority sources.
Deep reasoning (Long Context layer). The assembled context is injected into a large context window model. The model now operates over a focused, relevant set of documents rather than a massive, unfocused corpus - combining the scalability of RAG with the reasoning quality of Long Context.
Grounded response generation. The model generates a response grounded in the retrieved documents, with citations traceable back to source material.
Manufacturing example continued: The same industrial manufacturer later extended their field service assistant with a hybrid architecture for complex fault diagnosis. The RAG layer retrieved relevant service bulletins and fault histories from the full knowledge base. A Long Context model then reasoned across all retrieved documents holistically, identifying cross-references between bulletins, recognizing patterns across fault codes, and generating a ranked diagnostic hypothesis. Neither architecture alone would have delivered the same result.
What This Means for Your AI Roadmap
A few practical implications for IT and data leaders evaluating or scaling enterprise AI deployments.
Most organizations will end up with both. Different use cases within the same enterprise will favor different architectures. A compliance document review tool may be best served by Long Context; an enterprise-wide knowledge assistant over decades of records will need RAG. Plan for both patterns in your architecture standards.
Data quality is the common dependency. Whether you are building RAG pipelines or loading documents into a Long Context prompt, the quality of what reaches the model determines the quality of what it produces. Chunking strategy, document freshness, metadata accuracy, and deduplication all matter. Investment in a clean, well-governed content layer pays dividends regardless of which retrieval architecture you choose.
Instrument for retrieval quality. If RAG is in production, build monitoring to detect answer-grounding failures - cases where the model produces a response that is not supported by the retrieved documents. This failure mode is under-instrumented in most enterprise deployments, and in regulated industries it is a compliance exposure.
Context windows will keep expanding. The economics of Long Context are improving rapidly. An architecture that seemed cost-prohibitive at 2023 pricing may be viable at current pricing. Review your retrieval architecture choices annually as model capabilities evolve - what required RAG eighteen months ago may be a strong Long Context candidate today.
The fundamental challenge that models do not natively know your data is not going away. The retrieval architecture you build around it is not a workaround. It is core infrastructure. Getting it right early is one of the highest-leverage decisions in enterprise AI.