The Enterprise Context Plane: Implementing DataHub for AI-Ready Discovery, Governance, and Observability
Your data can stay exactly where it is. What your organization is missing is a unified layer of "data about your data": the context that makes discovery instant, governance enforceable, and AI agents trustworthy.
Date
February 16, 2026
Topic
Data
Share
AI Doesn't Fail on Model Quality. It Fails on Context.
Enterprises are not failing at AI because their models are weak. They are failing because their AI does not understand their data.
Modern data estates are fragmented across dozens of warehouses, lakes, BI platforms, orchestration engines, and ML systems, and no single layer holds the shared understanding of what the data means, where it came from, who owns it, and whether it can be trusted.
At Soul of the Machine, we address this gap by implementing DataHub, the leading open source AI data catalog and context platform, as an enterprise context plane: a unified metadata layer that powers AI-driven discovery, governance, and observability across the entire data landscape. Critically, DataHub never moves or copies your data. It creates a comprehensive layer of metadata, connecting every tool in your stack into a single, queryable graph that serves both human teams and AI agents.
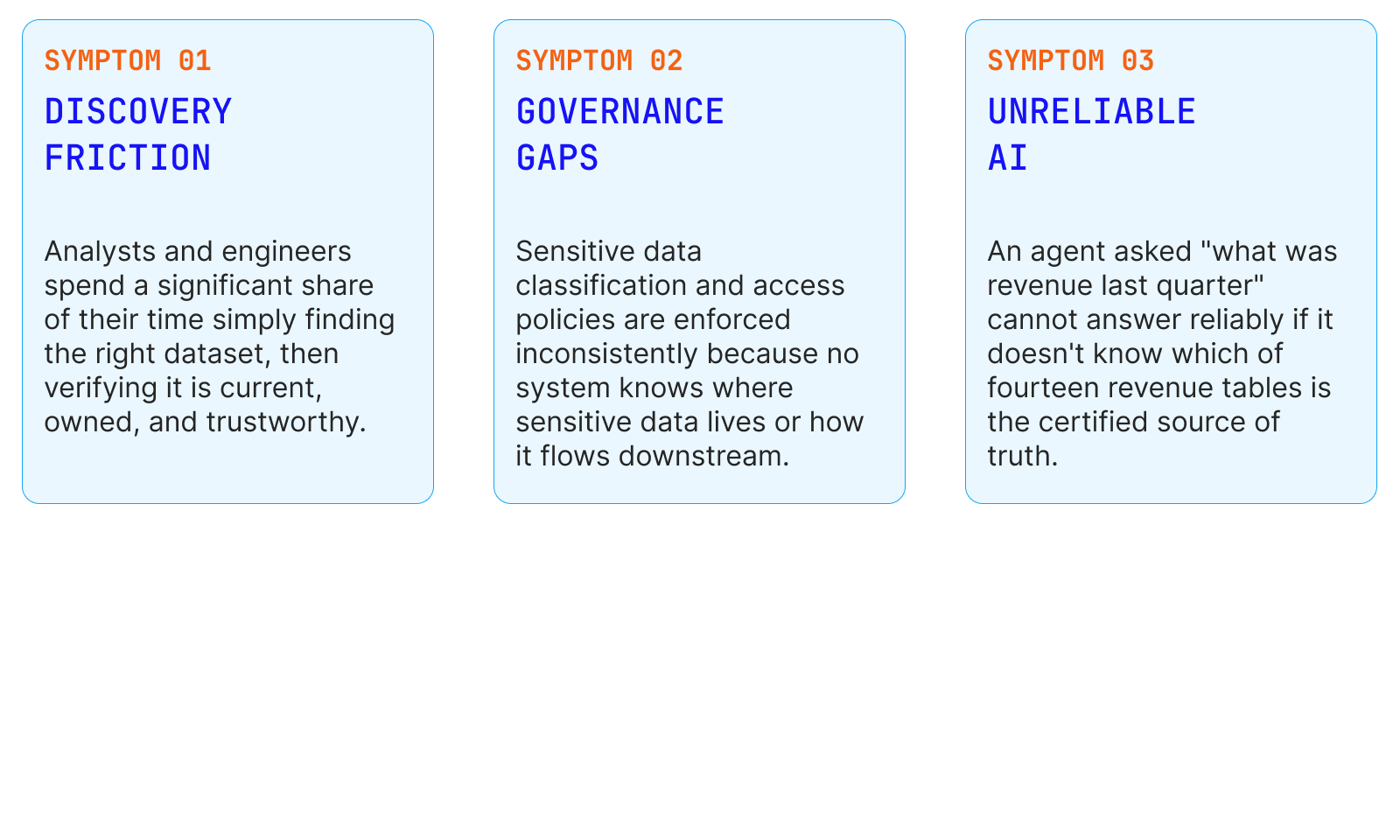
THE PROBLEM
Fragmented Data, Context-Starved AI
A typical enterprise data stack today spans Snowflake or BigQuery for warehousing, Databricks for lakehouse workloads, dbt and Airflow for transformation and orchestration, Tableau or Looker for BI, and a growing constellation of ML platforms and AI agents. Each tool maintains its own partial view of the data it touches. None of them sees the whole picture.
The root cause is the same in all three cases: the enterprise has data everywhere but context nowhere.
THE CONCEPT
What Is a Context Platform?
A context platform is a system of record for metadata: the technical, operational, and business knowledge that surrounds every data asset. Schemas, column-level lineage, ownership, documentation, usage statistics, quality assertions, classifications, and business glossary terms are all metadata. Individually, each fact is small. Connected into a graph, they become the context that makes data trustworthy and AI grounded.
DataHub, originally built at LinkedIn to manage metadata at hyperscale and open sourced in 2020 under the Apache 2.0 license, is the most widely adopted open source platform in this category. It runs in production at thousands of organizations across financial services, healthcare, retail, and technology, and has been proven at the scale of tens of millions of assets and on the order of a billion relationships.
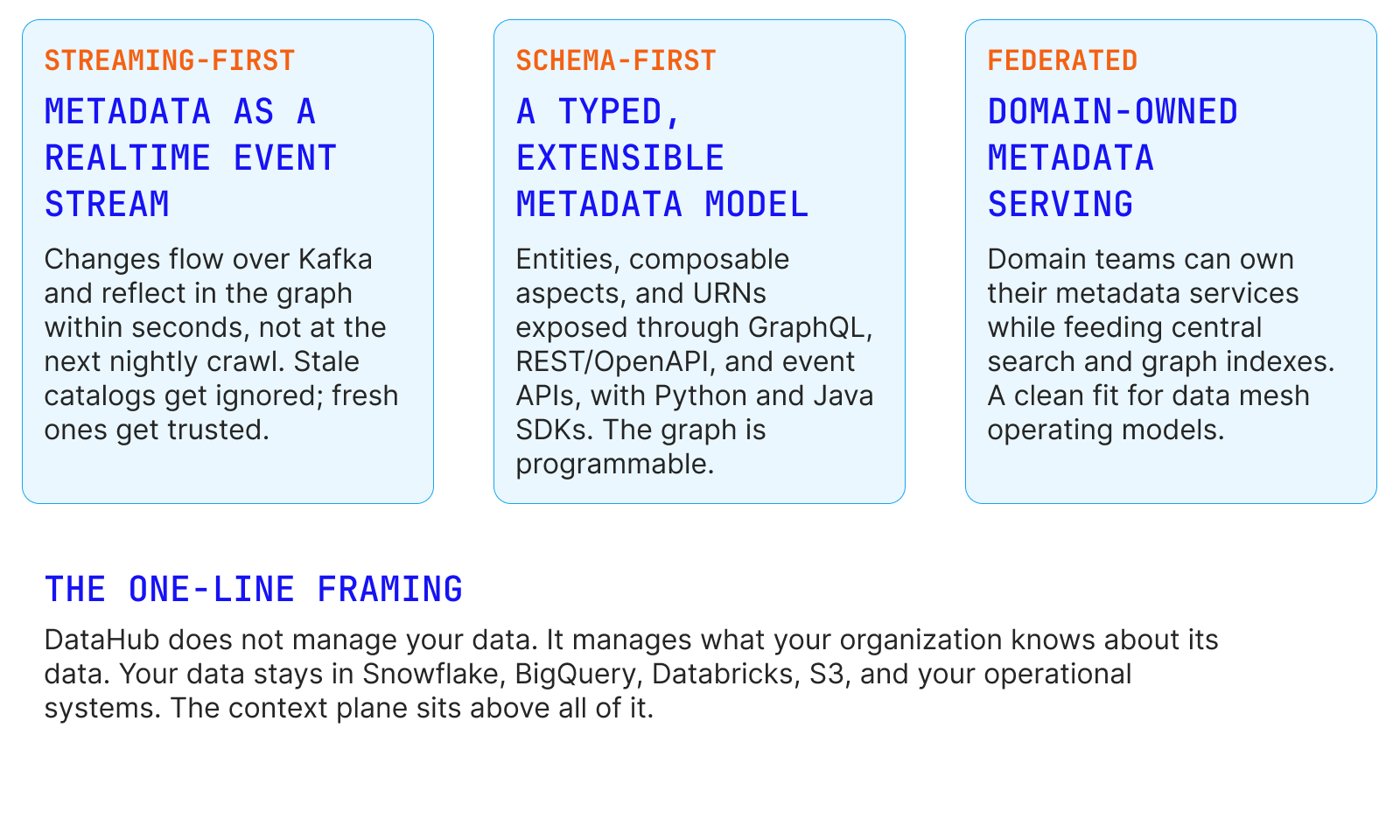
Three architectural decisions that matter
WHY NOW Context Is the Bottleneck for Agentic AI
Soul of the Machine designs and engineers agentic AI systems for the enterprise, and a consistent lesson from that work is that agent reliability is a context problem before it is a model problem. The most capable frontier model will still produce a wrong answer if it queries the wrong table.
DataHub has leaned directly into this with native AI integration. Its Model Context Protocol (MCP) server lets AI agents and assistants query the metadata graph directly: which datasets contain customer PII in production, the lineage of a revenue table, the schema and documentation for a dataset, all before writing a single line of SQL. Its open source Analytics Agent answers plain-English data questions by first consulting the catalog to find certified, well-documented assets. And because classifications, ownership, and policies live in the graph, metadata becomes enforceable guardrails for agentic workflows.
This is the strategic reframe we bring to clients: the data catalog is no longer a documentation tool for humans. It is runtime infrastructure for AI.
OUR APPROACH
The Soul of the Machine Four-Plane Implementation Framework
We structure every DataHub implementation around four planes. Each is a coherent unit of work with its own stakeholders, success criteria, and rollout sequence.
PLANE 1 / INGESTION Connect
Establish automated metadata flow from every system that produces or consumes data. DataHub's ingestion framework offers more than 80 production-grade connectors supporting both pull-based batch ingestion and push-based streaming, extracting schemas, column-level lineage, usage statistics, profiling, and quality signals. The design principle is coverage with depth: a catalog that sees only half the estate creates false confidence.
PLANE 2 / GRAPH Model
Shape raw ingested metadata into a coherent enterprise graph. URNs, domains, data products, business glossary terms, and ownership models are established here, and lineage is stitched across platform boundaries so a column in a Tableau dashboard traces back through dbt models to source tables.
PLANE 3 / HUMAN Activate
Turn the graph into daily-use capability for people: universal search, impact analysis before schema changes, automated classification and access policies, freshness and quality assertions, documentation and ownership. This is where data culture changes, and where catalogs historically stalled because the metadata was stale. Streaming-first ingestion keeps this plane alive.
PLANE 4 / AI Contextualize
Expose the graph to AI systems as governed context: MCP server deployment for agent and IDE integration, analytics agents grounded in certified assets, metadata-driven guardrails for agentic workflows, and event-driven automation through the DataHub Actions framework. This plane is typically why executive sponsors fund the program, and it only works because the three planes beneath it exist. The sequencing matters. Organizations that jump straight to Plane 4 build agents on sand. Organizations that stop at Plane 3 build an expensive documentation site. The four planes together produce a context plane that compounds in value as both humans and AI consume it.
ARCHITECTURE
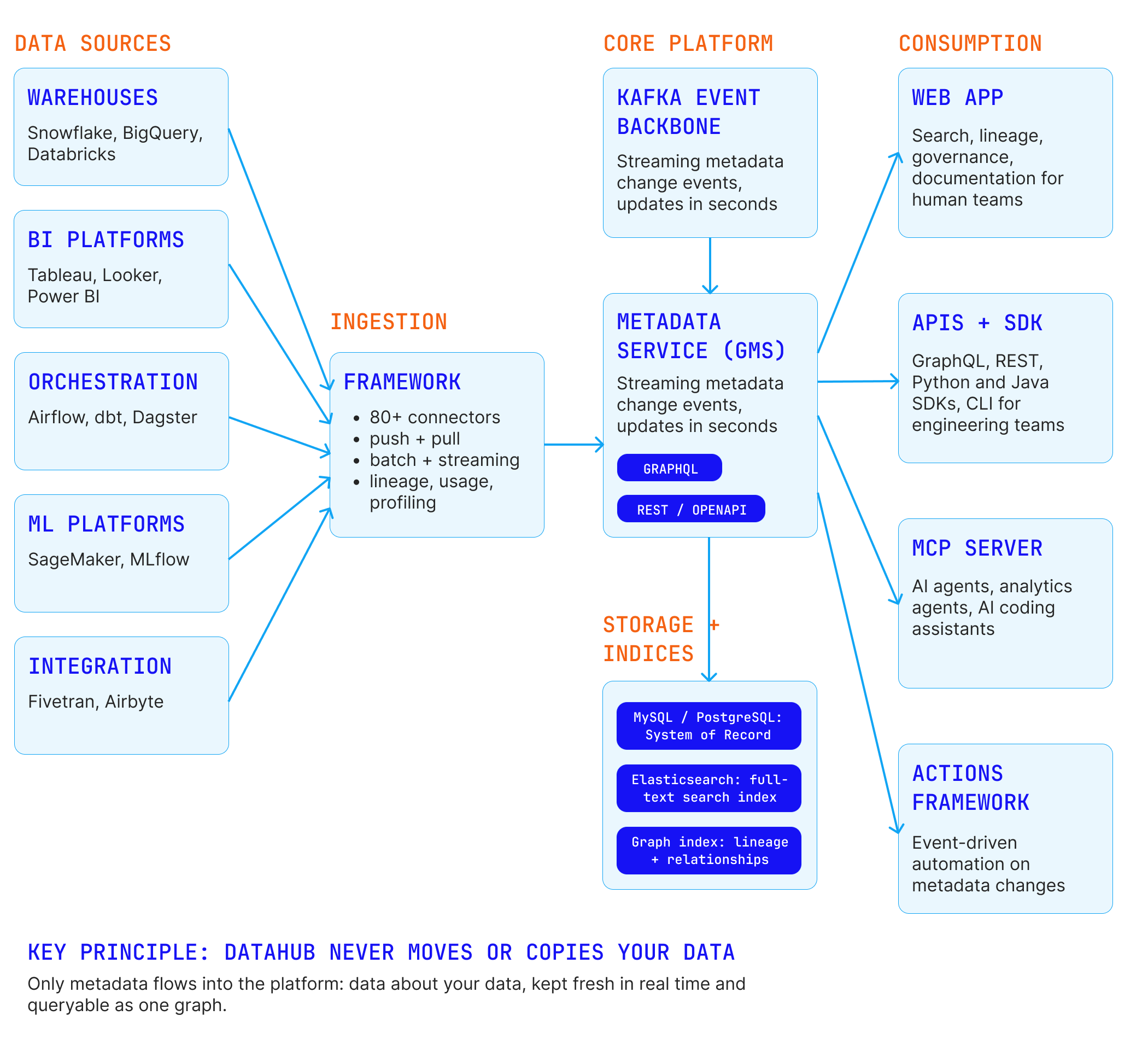
Reference Architecture
The deployment architecture we implement follows DataHub's cloud-native, streaming-first design. Metadata flows from sources through the ingestion framework onto a Kafka event backbone, where the metadata service (GMS) validates and persists it into a relational system of record, an Elasticsearch search index, and a graph index for lineage. Humans consume the graph through the web application; engineering teams through GraphQL, REST, and SDKs; AI agents through the MCP server and the Actions framework.
For deployment, we typically recommend Kubernetes with Helm for production self-hosted environments, Docker quickstart for evaluation, and DataHub Cloud where a managed SaaS posture fits the client's operating model. All three run the same metadata model, so the deployment decision does not lock in the metadata strategy.
AI ENABLEMENT
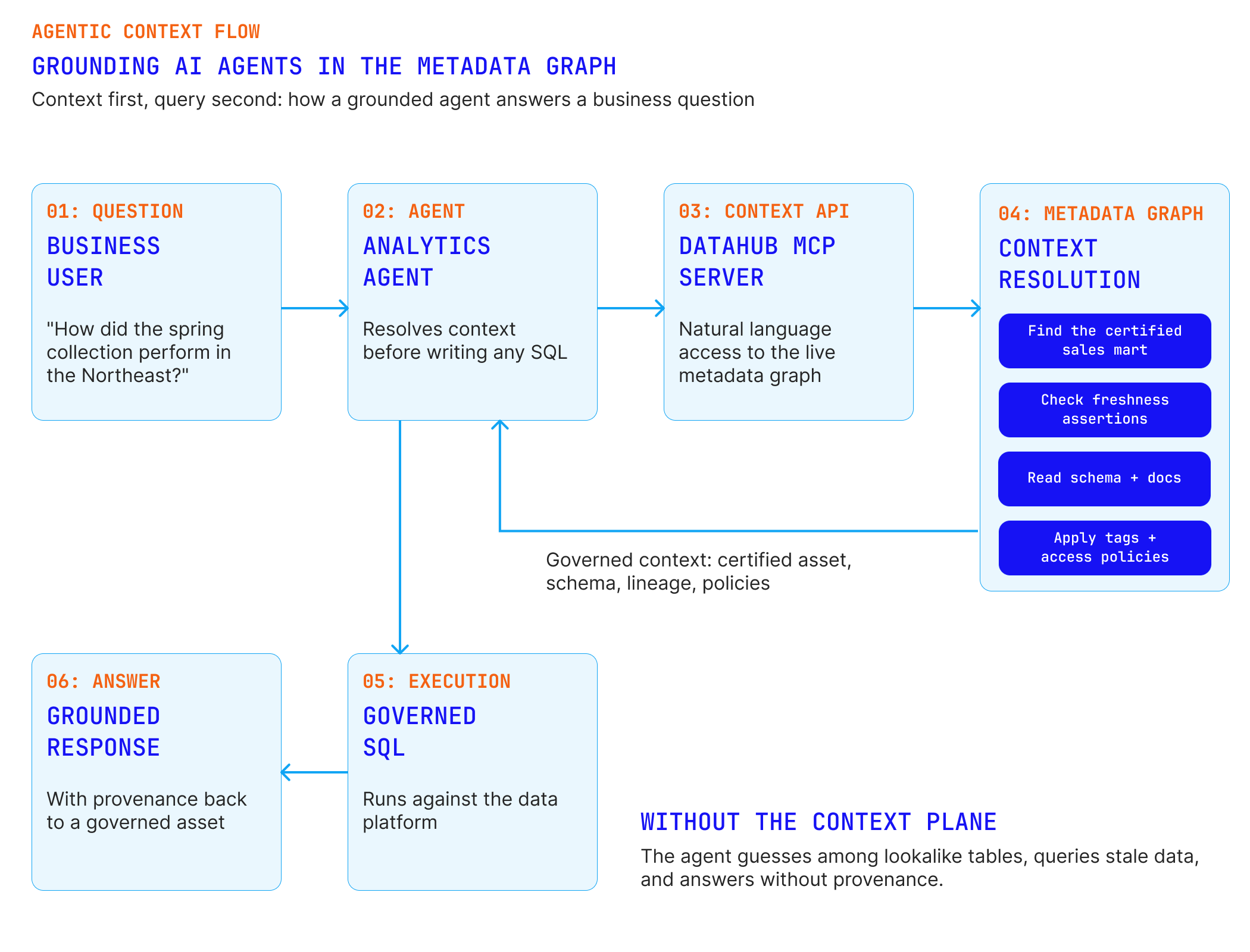
Grounding AI Agents in the Metadata Graph
The flow below shows what changes when an analytics agent resolves context before execution. Instead of guessing among lookalike tables, the agent uses MCP to find the certified asset, verify freshness, read documentation, and respect access policies, then generates SQL against a governed target and returns an answer with provenance.
IN PRACTICE
Usage Patterns from the Field
These patterns recur across our implementation work. The scenarios below are illustrative and sector-representative rather than descriptions of specific client engagements.
PATTERN 01: FINANCIAL SERVICES Impact analysis before change
A data engineering team at a bank needs to modify a column feeding regulatory reporting. Before the change, they query column-level lineage to see every downstream model, dashboard, and report that consumes the field, including the risk aggregation views regulators audit. A multi-day email archaeology exercise becomes a five-minute graph traversal, with documented blast-radius analysis attached to the change ticket.
A provider organization applies automated classification to detect PHI-bearing columns in its clinical data warehouse. Classifications propagate through lineage, so derived analytics tables inherit the sensitivity of their sources. Because metadata streams in real time, a newly added column containing patient identifiers can trigger an immediate access review rather than waiting for a quarterly audit.
PATTERN 03: RETAIL Grounded analytics agents
A retailer deploys a conversational analytics agent for merchandising teams, connected to DataHub through MCP. Questions like "how did the spring collection perform in the Northeast" resolve by first finding the certified sales mart, checking freshness assertions, and reading column documentation before generating SQL. Containment improves because the agent stops guessing, and every answer carries provenance back to a governed asset.
PATTERN 04: MANUFACTURING + SUPPLY CHAIN Data contracts across the supply chain
A manufacturer formalizes the interface between plant-floor telemetry pipelines and enterprise demand-planning models as data contracts: schema expectations, freshness SLAs, and volume assertions registered in DataHub. When an upstream firmware change alters a sensor payload, the contract violation surfaces within minutes through the event stream, before planning models consume bad data.
PATTERN 05: CROSS-INDUSTRY Shift-left metadata in CI/CD
Engineering teams wire impact analysis into the development workflow, so a pull request that modifies a dbt model is automatically annotated with the downstream assets it affects. Metadata validation becomes a merge gate rather than a post-incident investigation, moving governance from reactive to preventive.
DELIVERY
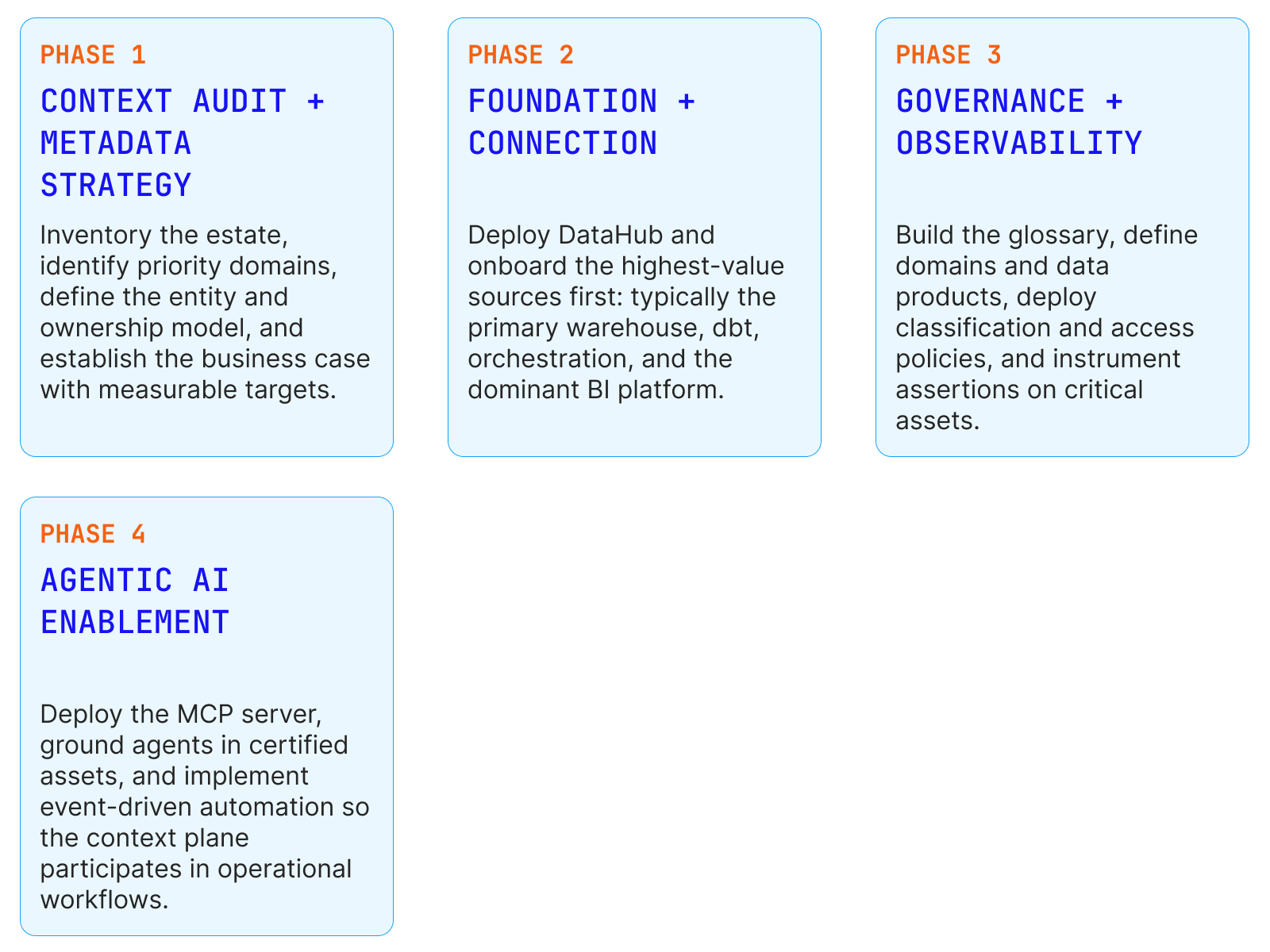
How Soul of the Machine Delivers a DataHub Implementation
OUTCOMES Measuring Success
We anchor each implementation to a small set of outcome metrics. Time to data: how long it takes a new analyst or an AI agent to locate, validate, and use the right asset. Governance coverage: the share of critical assets with assigned ownership, classification, and documented lineage. Change failure reduction: incidents caused by unreviewed schema or pipeline changes, before and after impact analysis is embedded in the workflow. AI answer reliability: for grounded agents, the rate at which answers trace to certified assets with verifiable provenance, measured alongside containment and resolution metrics.
THE BOTTOM LINE
What Does Your AI Actually Know About Your Data?
Every enterprise AI roadmap eventually collides with that question. DataHub, implemented as an enterprise context plane, is the most mature open source answer to it: discovery, governance, and observability unified in a single metadata graph, kept fresh through streaming ingestion, and exposed to both humans and AI agents through open APIs and MCP.
Soul of the Machine brings the agentic AI strategy, architecture, and engineering depth to make that context plane real: connected to your stack, modeled for your domains, activated for your teams, and contextualized for your AI.