GraphRAG: When Your Enterprise AI Needs to Understand Relationships, Not Just Retrieve Text
Standard RAG is the default starting point for enterprise AI, but it breaks down on relationship questions that vector similarity alone cannot answer. GraphRAG fills that gap, and in this article we explain how it works, where it outperforms standard RAG, where it adds unnecessary cost, and how Soul of the Machine approaches implementations.
Date
November 3, 2025
Topic
Data
Share
Most enterprise AI initiatives begin with the same architecture: take documents, chunk them, embed them in a vector database, and retrieve the most similar passages when a user asks a question. This pattern, Retrieval-Augmented Generation (RAG), has earned its place as the default starting point. It grounds large language models in your proprietary data, reduces hallucination, and gets a working assistant in front of users quickly.
Then the questions get harder. A risk analyst asks which suppliers in the third tier of the supply chain are exposed to a sanctioned entity. A clinician asks how a patient’s medication history interacts with a newly prescribed treatment given two comorbidities. A compliance officer asks which contracts reference an obligation that was amended in a regulation last quarter. These are not lookup questions. They are relationship questions, and vector similarity alone cannot answer them reliably.
This is the gap GraphRAG fills. In this article we explain what GraphRAG is, how the architecture works under the hood, where it genuinely outperforms standard RAG, where it adds cost and complexity you may not need, and how Soul of the Machine approaches GraphRAG implementations across industries.
What Is GraphRAG?
GraphRAG extends retrieval-augmented generation by grounding retrieval in a knowledge graph: an explicit, structured representation of the entities in your domain (customers, products, suppliers, patients, contracts, regulations) and the typed relationships that connect them (supplies, treats, references, owns, depends on).
In a standard RAG system, knowledge is a pile of independent text chunks ranked by semantic similarity to the question. The system knows that two passages are about similar topics, but it has no idea how the facts inside them relate. A knowledge graph changes that. It does not just know that a supplier and a manufacturer appear in the same documents. It knows the supplier provides a specific component, to a specific plant, under a specific contract, with a specific expiration date.
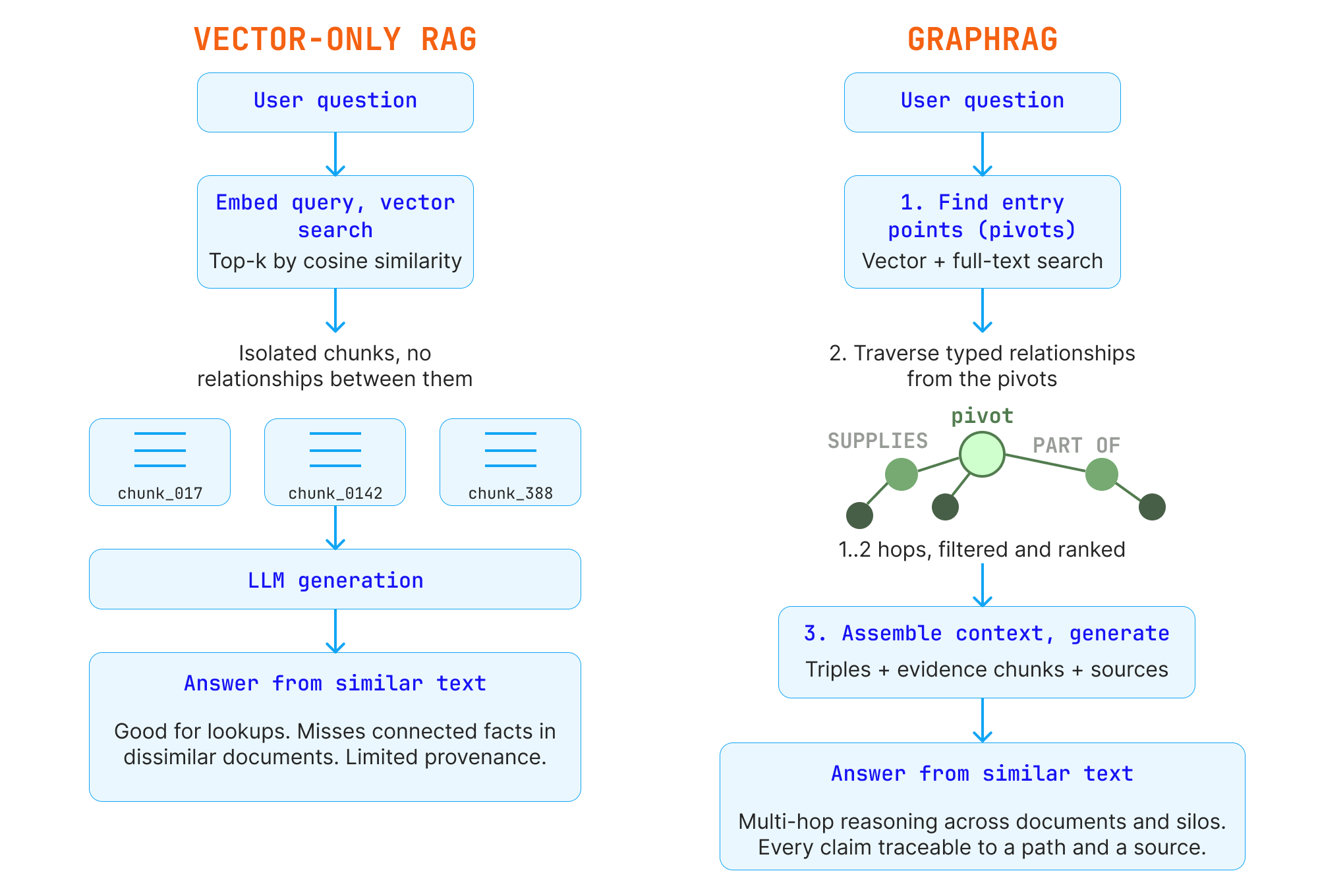
A typical GraphRAG retrieval works in three movements:
Find entry points. The user’s question is matched against the graph and its associated content using vector search, full-text search, or both. This identifies the most relevant starting nodes, sometimes called pivots.
Traverse relationships. From those entry points, the system follows typed relationships outward: one, two, or more hops, guided by the question. This relevance expansion surfaces connected facts that a similarity search would never retrieve because they live in documents that do not resemble the question at all.
Assemble grounded context. The retrieved entities, relationships, and supporting text are ranked, filtered, and assembled into the prompt. The LLM generates an answer from a context that carries structure and provenance, not just prose.
The critical architectural point: GraphRAG is not a replacement for vector search. It is a hybrid. Vector search remains an excellent way to find where to start. The graph determines where to go from there.
Vector-only RAG retrieves isolated chunks by similarity; GraphRAG finds entry points, then traverses typed relationships to assemble connected, traceable context.
The GraphRAG Reference Architecture
A production GraphRAG system is a pipeline of five cooperating layers, with observability spanning all of them. Understanding each layer, and where each one typically fails, is the difference between a demo and a system your risk function will approve.
The GraphRAG reference architecture: five cooperating layers with an observability and evaluation spine spanning construction through generation.
Layer 1: Data sources
GraphRAG earns its keep by unifying knowledge that lives in silos: document repositories and wikis, structured systems of record (ERP, CRM, PLM, EHR), event streams and APIs, and external feeds such as regulatory updates, market data, or supplier intelligence. The architecture must treat structured and unstructured sources as first-class citizens, because the highest-value relationships usually cross that boundary: a contract clause (unstructured) constraining a purchase order (structured).
Layer 2: Ingestion and graph construction
This is where most GraphRAG initiatives succeed or fail. The construction pipeline has four stages:
Chunking and embedding. Documents are split into retrievable units and embedded for the vector index, exactly as in standard RAG. The difference is that chunks are not the end product; they are anchored to the graph through relationships such as MENTIONS or FROM_CHUNK, preserving the link between extracted facts and their textual evidence.
Entity and relationship extraction. An LLM-based extraction pass identifies domain entities and the typed relationships between them in each chunk, constrained by the ontology (more on that below). Constraining extraction matters: an unconstrained LLM will invent creative relationship types for every document, and you will end up with forty synonyms for “supplies.” We enforce closed sets of node labels and relationship types, require structured (JSON) output, and run extraction at temperature zero.
Entity resolution. “Acme Corp,” “ACME Corporation,” and “Acme (UK) Ltd” must converge on one node, or your traversals silently miss connections. Production-grade resolution combines deterministic matching on identifiers (DUNS numbers, MRNs, SKUs), embedding similarity for fuzzy name matching, and LLM adjudication for ambiguous cases. This stage deserves more engineering investment than any other; a graph with poor resolution is worse than no graph, because it produces confidently incomplete answers.
Validation and human review. Schema validation rejects extractions that violate the ontology (a Drug cannot SUPPLY a Plant). For high-stakes relationship types, such as ownership chains in financial crime contexts or contraindications in clinical contexts, a human-in-the-loop review queue gates writes to the graph.
Layer 3: The knowledge layer
Three assets live here, and they are deliberately separate concerns:
The ontology (semantic model). A pragmatic definition of entity types, relationship types, and their properties. We stress pragmatic: the ontology should be the minimum model needed to answer the target question patterns, not an academic map of the enterprise. A useful starting ontology for a supply chain use case might be eight node labels and a dozen relationship types. It will grow; let it grow from evidence.
The knowledge graph itself, stored in a graph database that supports efficient traversal and a mature query language (Cypher, GQL, or equivalent). Property graphs are the dominant choice for GraphRAG because relationships carry attributes: a SUPPLIES edge can hold contract dates, volumes, and sole-source flags that retrieval can filter on.
The indexes. Vector indexes over chunk and entity embeddings, full-text indexes over names and descriptions, and optionally precomputed graph signals such as community assignments or PageRank scores. Entry-point search quality depends on these indexes, and they must be rebuilt or incrementally updated as the graph evolves.
Layer 4: Retrieval and ranking
Retrieval in GraphRAG is a composition: find entry points, expand through the graph, then rank and prune before anything reaches the model. Expansion without pruning is a classic failure mode; a two-hop neighborhood around a popular node can contain thousands of facts, and stuffing them into the prompt buries the signal. Effective ranking combines the entry-point similarity score, path length (closer facts score higher), relationship-type weights set per use case, and recency or validity properties on the edges themselves.
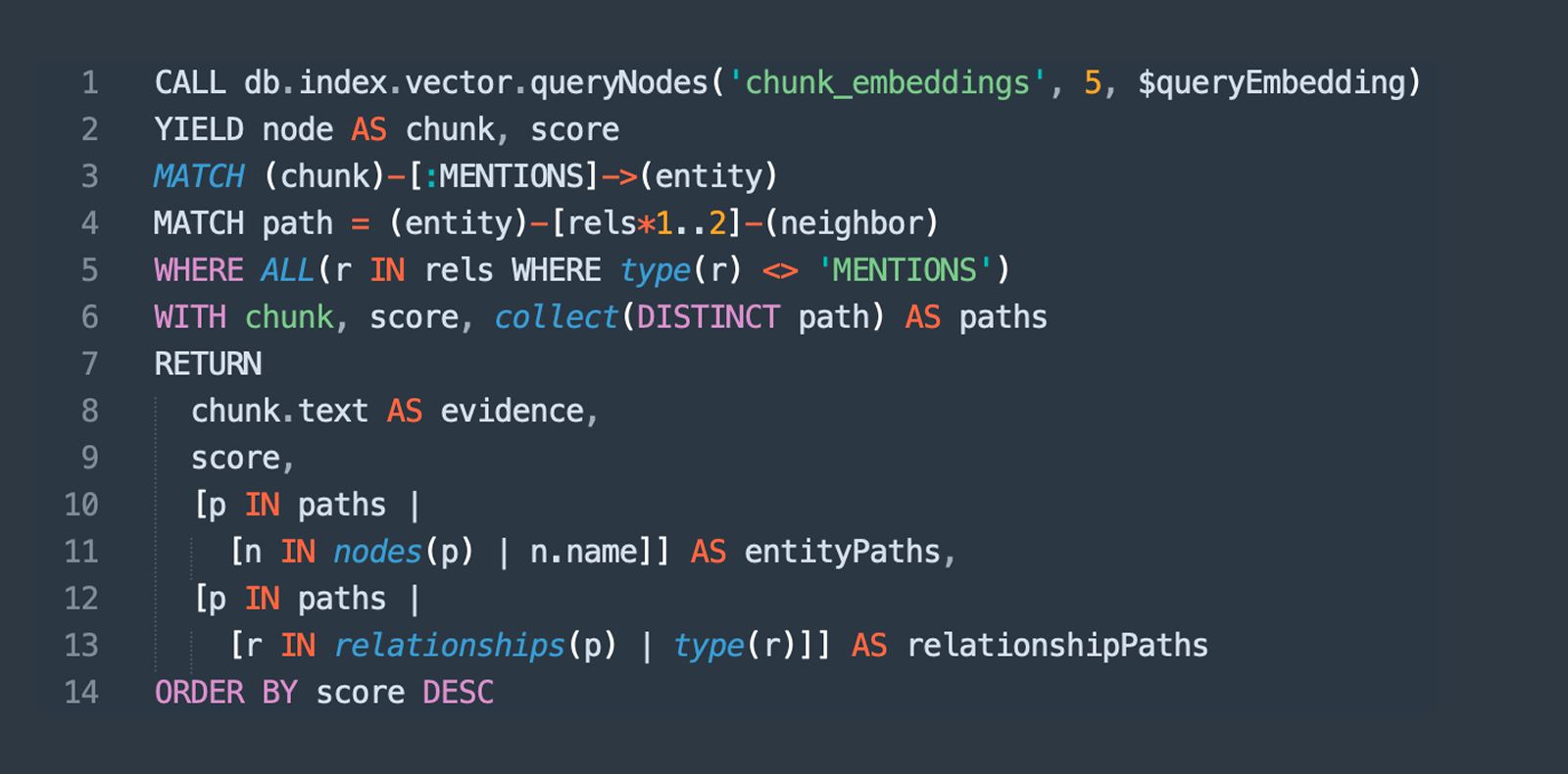
To make this concrete, here is the shape of a hybrid retrieval query in Cypher. It finds entry chunks by vector similarity, walks out to the entities they mention and their two-hop neighborhood, and returns both the supporting text and the relationship triples.
The exact query is use-case specific; the pattern (index search, constrained traversal, structured return of evidence plus triples) is universal.
Layer 5: Orchestration and generation
In modern deployments, retrieval strategies are exposed as tools that an agent selects and sequences. A router classifies the incoming question (lookup, comparative, multi-hop, structural, aggregate) and dispatches it: simple lookups go straight to vector retrieval to protect latency and cost, while relational questions invoke graph retrievers, potentially iteratively, until the agent judges the context sufficient. The generation step then receives curated context with explicit provenance: which entities, which relationships, which source chunks. The prompt instructs the model to answer only from this context and to cite the supporting paths.
The observability spine
Spanning every layer is the discipline that makes GraphRAG operable: extraction quality metrics and drift detection, graph health (orphan nodes, resolution collision rates, coverage gaps), retrieval traces showing exactly which paths fed each answer, and answer-level evaluation (faithfulness, retrieval precision and recall, hop-depth coverage) against a curated question set. A retrieval system you cannot inspect is a retrieval system you cannot trust or improve.
The Retriever Toolbox
“GraphRAG” is not one retrieval algorithm. Production systems compose several patterns, each suited to a class of question. The six we deploy most often:
Entry-point search. Vector, full-text, or hybrid search to locate starting nodes. This is the front door for every other pattern.
Neighborhood traversal. Expand one to two hops around an entity to enrich it with context. Suited to “tell me about X” questions where X’s immediate relationships are the answer.
Path traversal. Find and walk paths between two or more entities. This is the workhorse for multi-hop questions: exposure chains, root-cause analysis, dependency tracing.
Query templates. Expert-authored parameterized queries for known question categories. When the compliance team asks the same six question shapes every week, templates deliver deterministic, auditable retrieval with no generation risk.
Dynamic query generation (text-to-Cypher). An LLM generates a graph query from the question and the schema description. Powerful for structural and aggregate questions (“how many sole-source suppliers feed plants in region X”), but it requires guardrails: schema-constrained generation, query validation, read-only execution, and result-size limits.
Agentic traversal. The LLM plans and sequences the retrievers above, inspecting intermediate results and deciding what to fetch next. This handles open-ended investigative questions at the cost of latency and token spend, so we reserve it for workloads where the investigation itself is the value.
The retriever toolbox: production GraphRAG composes six retrieval patterns, dispatched per question by a router or agent.e image caption here (optional)
Where GraphRAG Outperforms, and What It Costs You
The pros
Multi-hop reasoning. Questions that chain across entities (supplier > component > product > customer, or drug > interaction > condition > patient) are answered by traversal rather than by hoping the right chunks happen to rank highly. This is the single biggest quality gain.
Explainability and auditability. Every answer can be traced back to a path through the graph: which entities, which relationships, which source documents. In regulated industries this is not a nice-to-have. It is the difference between an AI capability your risk function approves and one it shuts down.
Cross-document and cross-silo synthesis. Because entities are resolved to a shared model, facts about the same customer or asset that live in a CRM, a contract repository, and a ticketing system converge on the same node. The system reasons over the whole, not over fragments.
Consistency through shared semantics. An ontology, even a lightweight one, forces the enterprise to agree on what a “customer,” “account,” or “incident” actually is. Retrieval then aligns with enterprise definitions instead of surface wording, which varies wildly across teams and documents.
Freshness without retraining. Graphs evolve incrementally. New entities and relationships are added as the business changes, and the retrieval layer benefits immediately. There is no model fine-tuning cycle and no full re-embedding of the corpus.
The cons
Construction effort is real. Extracting entities and relationships from unstructured text at enterprise quality requires careful pipeline design, prompt engineering, entity resolution, and human review loops. Poor extraction produces a noisy graph, and a noisy graph produces confidently wrong answers with very convincing-looking provenance.
Ongoing curation is a commitment. A knowledge graph is a product, not a project. It needs ownership, governance, and a process for handling schema evolution, conflicting facts, and data decay. Organizations that treat it as a one-time ingestion job watch its value erode within months.
Higher architectural complexity. You are now operating a graph database, an extraction pipeline, a retrieval and ranking layer, and an orchestration layer, in addition to everything a standard RAG stack requires. That means more skills, more failure modes, and more observability surface.
Latency and cost overhead. Traversals, ranking, and larger assembled contexts add inference and query cost. For simple lookup questions, GraphRAG is slower and more expensive while delivering no measurable quality improvement.
It does not fix bad data. If your underlying sources are contradictory or stale, the graph will faithfully encode contradictions and staleness. GraphRAG amplifies the value of well-governed data and the visibility of poorly governed data.
What to Consider Before Picking GraphRAG
We advise clients to work through five questions before committing to a GraphRAG architecture.
1. What shape are your questions? Audit the actual queries your users ask or will ask. If the majority are single-fact lookups (“what is our parental leave policy”), standard RAG with good chunking and reranking will serve you well at a fraction of the cost. If a meaningful share are relational, comparative, or multi-hop (“which policies changed after the reorg and which teams are affected”), GraphRAG starts paying for itself.
2. Does your domain have a natural graph structure? Supply chains, financial networks, clinical pathways, product hierarchies, regulatory obligations, and organizational knowledge are inherently connected domains. A corpus of largely independent documents, like a marketing asset library, is not. Match the architecture to the shape of the knowledge.
3. What is your explainability requirement? If answers feed decisions that auditors, regulators, or clinicians must trust and verify, the traceable reasoning paths of GraphRAG may be a requirement rather than an enhancement. If the use case is low-stakes internal productivity, the bar is lower.
4. Can you sustain the graph? Be honest about data governance maturity and ownership. Someone must own the ontology, the extraction quality, and the update cadence. If no team can carry that, start with standard RAG and build governance muscle first.
5. Can you start small? The best GraphRAG adoptions we have seen do not boil the ocean. They model one high-value domain, prove quality lift against a baseline RAG system on a fixed evaluation set, and expand from there. If you cannot define the evaluation set, you are not ready to choose an architecture at all.
A useful rule of thumb: GraphRAG is justified when answer quality on relationship-heavy questions is a business problem, when explainability is a requirement, and when the organization can commit to graph stewardship. If any of those three is missing, standard RAG, possibly with reranking and metadata filtering, is the more responsible choice.
How Soul of the Machine Implements GraphRAG
At Soul of the Machine, we treat GraphRAG as one retrieval strategy within a broader agentic architecture, not as a product to be installed. Our implementations follow a four-phase approach.
Phase 1: Question-pattern analysis and architecture fit. We begin by instrumenting or sampling the real questions the business needs answered, then classifying them: lookup, comparative, multi-hop, temporal, aggregate. This analysis determines whether GraphRAG is warranted at all, and if so, for which slice of the workload. Many engagements result in a hybrid recommendation where a router sends simple queries down a lean vector path and relational queries down the graph path.
Phase 2: Domain modeling and graph construction. Working with the client’s domain experts, we define a pragmatic ontology: the minimum set of entity types and relationships needed to answer the target question patterns, not an academic model of the entire enterprise. We then build extraction pipelines that combine LLM-based entity and relationship extraction with deterministic ingestion from structured systems, entity resolution to merge duplicates, and human-in-the-loop review for high-stakes relationship types.
Phase 3: Hybrid retrieval and agentic orchestration. We implement retrieval as a toolbox rather than a single query: vector and full-text search for entry points, neighborhood and path traversals for expansion, templated graph queries for known question categories, and dynamic query generation for structural questions. In agentic deployments, these retrievers become tools the agent selects and sequences, which fits naturally into the orchestration frameworks we work with, such as LangGraph, and into cloud-native agent platforms like Vertex AI Agent Builder.
Phase 4: Evaluation and observability. Every GraphRAG system we deliver ships with an evaluation harness that compares answer quality against the baseline RAG approach on a curated question set, plus production observability covering retrieval traces, graph coverage gaps, extraction drift, and answer provenance. This connects directly to our AI observability practice: a retrieval system you cannot inspect is a retrieval system you cannot trust or improve.
What this looks like across industries
Financial services. A global bank’s counterparty risk function needs to answer questions like “what is our aggregate exposure to entities connected to this sanctioned organization within three ownership hops.” Ownership, control, and transaction relationships are modeled in the graph; vector search over filings and news provides entry points; traversal surfaces the exposure chain with full provenance for the compliance file.
Healthcare. A health system deploying a clinical knowledge assistant connects patient records, medication catalogs, interaction databases, and care guidelines under a shared clinical model. When a clinician asks about treatment options for a patient with multiple conditions, the system traverses condition > guideline > contraindication > medication paths and cites the exact sources behind each step, which is essential for clinical trust.
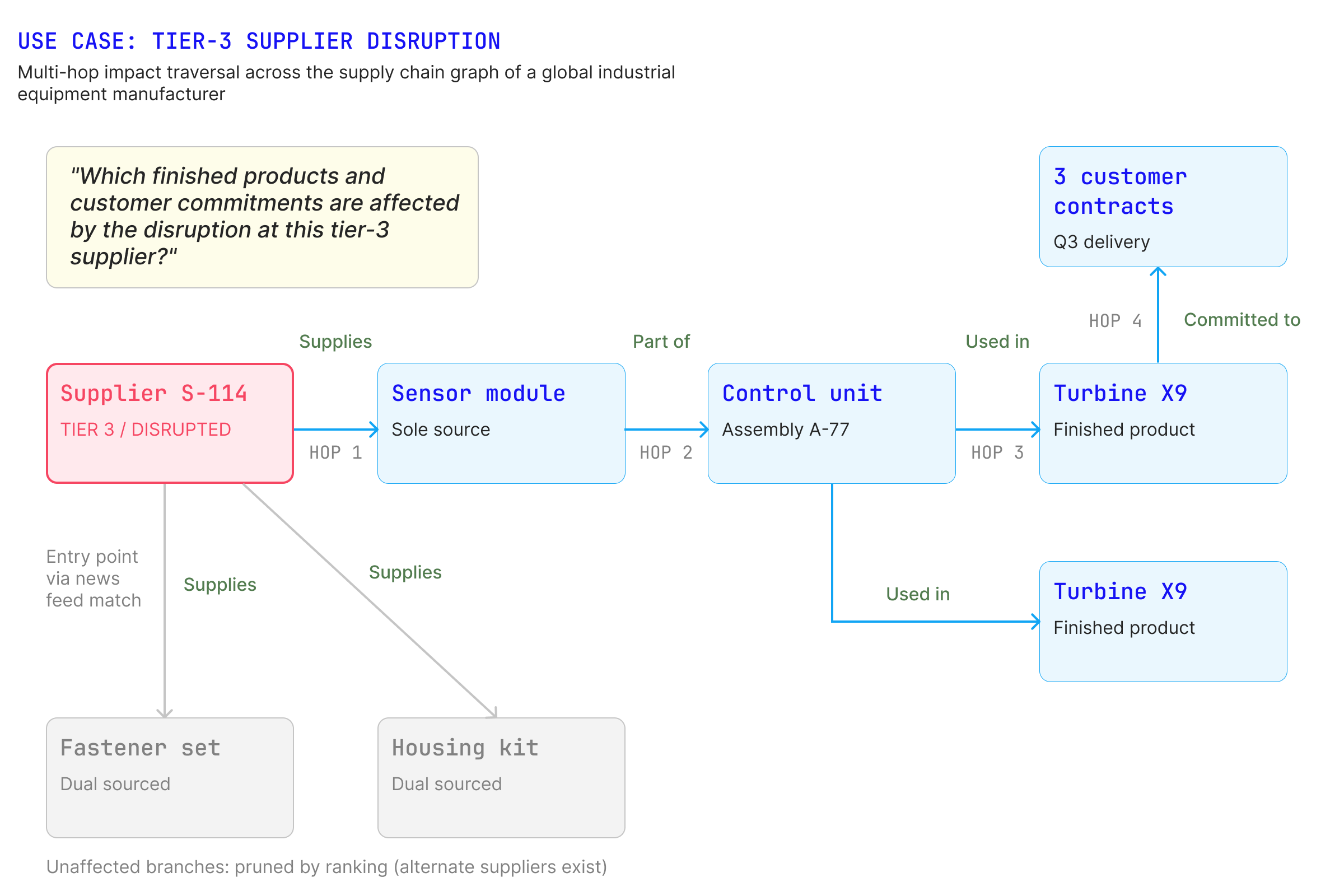
Manufacturing and supply chain. A global industrial equipment manufacturer models suppliers, components, plants, and bills of materials as a graph. When a regional disruption hits, the question “which finished products and customer commitments are affected by this tier-three supplier” becomes a traversal completed in seconds, rather than a week of spreadsheet archaeology.
Tier-3 supplier disruption traversal: from a news-feed entry point, the graph surfaces the sole-sourced exposure chain to products and customer commitments, pruning dual-sourced branches.
Retail and e-commerce. A retailer’s customer service agents draw on a product graph linking items, compatibility relationships, return policies, and order histories. The agent can answer “will this accessory work with the model I bought last year, and if not, what are my options” by walking actual compatibility relationships instead of guessing from product description similarity.
The Bottom Line
GraphRAG is not the next mandatory upgrade for every RAG system. It is a deliberate architectural choice for organizations whose hardest questions are about how things connect, and whose stakes demand answers that can be explained and audited. When those conditions hold, the quality gap between GraphRAG and vector-only retrieval is not incremental. It is the difference between an assistant that retrieves text and a system that reasons over your enterprise’s knowledge.
If you are weighing whether your AI initiative has outgrown vector-only retrieval, that assessment is exactly where we start. Soul of the Machine helps enterprises evaluate the fit, model the domain, and deliver GraphRAG systems with the evaluation and observability discipline they deserve.